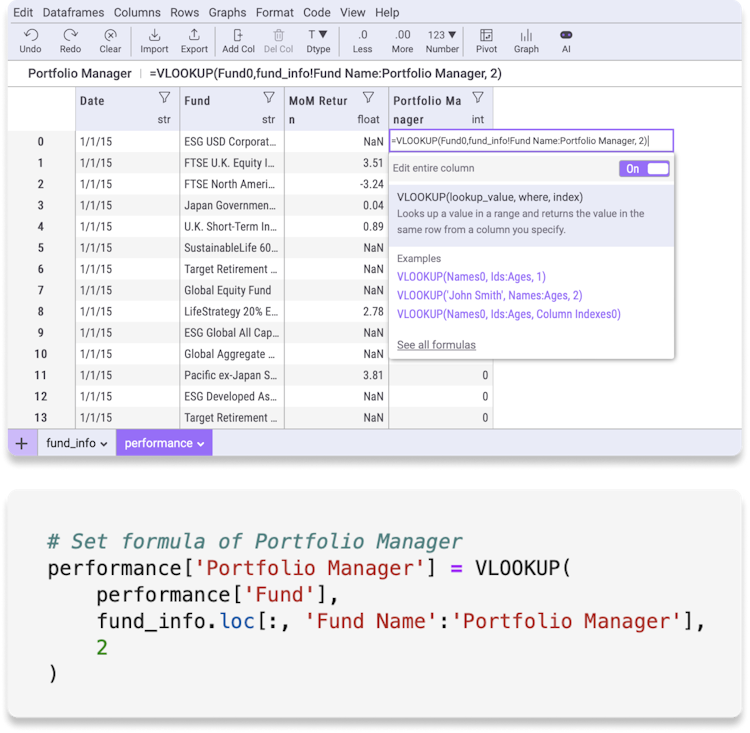
Functions
Lookup
INDEX MATCH
How to Use Excel's INDEX MATCH Function in Pandas
Excel's INDEX MATCH combo is a powerful tool to perform lookups, offering more flexibility than the VLOOKUP function. This combination of functions allows you to search for a value in one column and return a corresponding value from any other column.
This page explains how to emulate the functionality of Excel's INDEX MATCH in Python using pandas.
Implementing the Lookup and Match function in Pandas#
To emulate the INDEX MATCH functionality in Excel using Python and pandas, you can utilize various techniques based on your specific needs. Here are some common implementations:
Basic Index Matching#
Imagine that you have the following two sheets in Excel:
Sheet1 has a list of foods in column A
Sheet2 has a list of foods in column A and the quantities sold for the months January, February, and March in columns B, C, and D respectively
In Excel, if you wanted to find the quantity of each food sold in January, you could use the following formula in Sheet 1, column B, row 2: =INDEX(Sheet2!$A$2:$D$4,MATCH(Sheet1!A2,Sheet2!$A$2:$A$4, 0), 2). In other words, you're searching for the value in Sheet1!A2 (Apple) in the range Sheet2!$A$2:$A$4 (Apple, Banana, Orange) and returning the corresponding value from the second column (Jan)
To perform the same operation in pandas, you can use pandas' merge function, which is a powerful way to perform database-like joins on two DataFrames. In this case, we're performing a left join on the 'Food' column of df1 and df2, which is similar to Excel's INDEX MATCH. The 'Food' column is the column that we're searching for the value in, and the 'Jan Quantity' column is the column that we're returning the value from.
Notice that there are a few important differences between the Excel and pandas implementations:
Firstly, instead of referencing the columns we want to return by their index, we reference them by their name. In this example, to return the data for January, instead of specifying that we want data from column 2, like we did in INDEX MATCH, we specify that we want data from the 'Jan Quantity' column.
Secondly, we have to remove duplicate values from df2 so that we only find the first match, just like Excel's INDEX MATCH. If we didn't do this, we would get multiple matches for each food, and the merge would return a row for each match.
import pandas as pd
df1 = pd.DataFrame({'Food': ['Apple', 'Banana', 'Orange']})
df2 = pd.DataFrame({
'Food': ['Apple', 'Banana', 'Orange'],
'Jan Quantity': [100, 50, 40],
'Feb Quantity': [105, 55, 45],
'Mar Quantity': [110, 60, 50]
})
# Remove duplicate Foods from df2 so we only find the first match,
# just like Excel's INDEX MATCH
df2 = df2.drop_duplicates(subset=['Food'])
# Only keep the Food and Jan Quantity columns from df2 so that
# only return the Jan Quantity column from df2
df2 = df2[['Food', 'Jan Quantity']]
# Merge the two dataframes together on the Food column
merged_df = pd.merge(df1, df2, left_on='Food', right_on='Food', how='left')
Populating an entire table with Index Match#
It's common to use INDEX MATCH formula in Excel to not just return a single column, but to populate an entire table. For example, imagine that you have the following two sheets in Excel:
Sheet1 has a list of foods in column A and their prices in column B
Sheet2 has a list of foods in column A and the quantities sold for the months January, February, and March in columns B, C, and D respectively
If you wanted to add Revenue January, Revenue February, Revenue March columns to Sheet 1, you could use a INDEX MATCH formula in columns C, D and E. For example, in Sheet 1, column C, row 2, you could use the following formula: =INDEX(Sheet2!$A$2:$D$4,MATCH(A2,Sheet2!$A$2:$A$4, 0), 2) * B2. In other words, you're searching for the value in Sheet1!A2 (Apple) in the range Sheet2!$A$2:$A$4 (Apple, Banana, Orange) and returning the corresponding value from the second column (Jan), then multiplying it by the value in B2 (the price of an Apple).
You would then copy this formula to columns D and E to get the values for February and March.
To perform the same operation in pandas, you can use pandas' merge function to return the values in the 'Jan Quantity', 'Feb Quantity', and 'Mar Quantity' columns all in one line of code.
import pandas as pd
df1 = pd.DataFrame({
'Food': ['Apple', 'Banana', 'Orange'],
'Price': [1, 2, 3]
})
df2 = pd.DataFrame({
'Food': ['Apple', 'Banana', 'Orange'],
'Jan Quantity': [100, 50, 40],
'Feb Quantity': [105, 55, 45],
'Mar Quantity': [110, 60, 50]
})
# Remove duplicate Foods from df2 so we only find the first match,
# just like Excel's INDEX MATCH
df2 = df2.drop_duplicates(subset=['Food'])
# Merge the two dataframes together on the Food column
merged_df = pd.merge(df1, df2, left_on='Food', right_on='Food', how='left')
# Multiply the Quantity columns by Price to get the Revenue columns
merged_df['Revenue January'] = merged_df['Price'] * merged_df['Jan Quantity']
merged_df['Revenue February'] = merged_df['Price'] * merged_df['Feb Quantity']
merged_df['Revenue March'] = merged_df['Price'] * merged_df['Mar Quantity']
# Only keep the columns we want
merged_df = merged_df[['Food', 'Price', 'Revenue January', 'Revenue February', 'Revenue March']]Index Match with Multiple MATCH Criteria#
Sometimes it's not enough to match based on a single column. Instead, you need to match based on multiple columns. For example, imagine that you have the following two sheets in Excel:
Sheet 1 has a list of foods in column A, store locations for columm B, and prices in column C
Sheet 2 has a list of foods in column A, store locations in column B, and quantities sold for the months January, February, and March in columns C, D, and E respectively
If you wanted to calculate the monthly revenue for each food for each store, you'd need to match based on both the food and store columns. In Excel, you could use the following formula in Sheet 1, column D, row 2: =INDEX(Sheet2!$C$2:$C$100, MATCH(A2 & B2, Sheet2!$A$2:$A$100 & Sheet2!$B$2:$B$100, 0)). The formula is similar to the previous example, except that the MATCH function now concatenates the food and store columns before searching for a match.
We can take a very similar approach in pandas. The only difference is that we need to create a new column that concatenates the food and store columns before merging the two dataframes together.
import pandas as pd
df1 = pd.DataFrame({
'Food': ['Apple', 'Banana', 'Orange', 'Apple', 'Banana', 'Orange'],
'Store': ['NYC', 'NYC', 'NYC', 'LA', 'LA', 'LA'],
'Price': [1, 2, 1, 1.5, 2.5, 1.5]
})
df2 = pd.DataFrame({
'Food': ['Apple', 'Banana', 'Orange', 'Apple', 'Banana', 'Orange'],
'Store': ['NYC', 'NYC', 'NYC', 'LA', 'LA', 'LA'],
'Jan Quantity': [100, 50, 43, 63, 42, 13],
'Feb Quantity': [105, 55, 52, 68, 47, 17],
'Mar Quantity': [100, 80, 67, 73, 52, 23]
})
# Drop duplicates from df2 on the Food and Store columns
df2 = df2.drop_duplicates(subset=['Food', 'Store'])
# Merge df1 and df2 on the Food and Store columns
merged_df = df1.merge(df2, left_on=['Food', 'Store'], right_on=['Food', 'Store'], how='left')
# Create the Revenue column for each month
merged_df['Jan Revenue'] = merged_df['Price'] * merged_df['Jan Quantity']
merged_df['Feb Revenue'] = merged_df['Price'] * merged_df['Feb Quantity']
merged_df['Mar Revenue'] = merged_df['Price'] * merged_df['Mar Quantity']
# Delete the columns we no longer need
merged_df = merged_df.drop(columns=['Price', 'Jan Quantity', 'Feb Quantity', 'Mar Quantity'])Case-Insensitive Index Matching#
By default, pandas' merging is case-sensitive. To perform a case-insensitive lookup, you need to adjust the key columns.
In Excel, using UPPER or LOWER with INDEX MATCH can ensure case-insensitive matching.
In pandas, this involves converting both key columns to lowercase (or uppercase or propercase) before the merge:
import pandas as pd
df1 = pd.DataFrame({
'Food': ['APPLE', 'BANANA', 'ORANGE'],
})
df2 = pd.DataFrame({
'Food': ['apple', 'banana', 'orange'],
'Jan Quantity': [100, 50, 43],
'Feb Quantity ': [105, 55, 52],
'Mar Quantity': [100, 80, 67]
})
# Drop duplicates from df2 on the Food and Store columns
df2 = df2.drop_duplicates(subset=['Food'])
# Convert the Food column to proper case
df1['Food'] = df1['Food'].str.title()
df2['Food'] = df2['Food'].str.title()
# Merge df1 and df2 on the Food and Store columns
# For each row in df1, find the best match in df2
df1['best_match'] = df1['Food'].apply(lambda x: process.extractOne(x, df2['Food'].tolist()))
df1['best_match'] = df1['best_match'].apply(lambda x: x[0])
# Only keep the columns from df2 that we want in our merged dataframe
df2 = df2[['Food', 'Jan Quantity']]
# Merge df1 to df2 on the best_match column
merged_df = df1.merge(df2, left_on=['best_match'], right_on=['Food'], how='left')
# Remove columns used for matching that we no longer need
merged_df = merged_df.drop(columns=['Food_y', 'best_match'])Lookup with Fuzzy Matching#
Sometimes, exact matching might not be sufficient due to slight discrepancies in data. For example, if you want to match the word 'Apple' with 'APPLE', 'apple', and 'Appl', the easiest way to do so is using fuzzy matching.
Fuzzy matching finds text strings that are likely to be the same even though there may be small differences.
To use fuzzy INDEX MATCH in Excel, you need to use third-party add-ins. Similarly, to perform a fuzzy match in Python, you need to install a third-party, open source (that means its free!) library. The most popular library for fuzzy matching is called `fuzzywuzzy`.
from fuzzywuzzy import process
import pandas as pd
df1 = pd.DataFrame({
'Food': ['Apple', 'Banana', 'Orange'],
})
df2 = pd.DataFrame({
'Food': ['Appl', 'BANANA', 'orange'],
'Jan Quantity': [100, 50, 43],
'Feb Quantity ': [105, 55, 52],
'Mar Quantity': [100, 80, 67]
})
# Drop duplicates from df2 on the Food and Store columns
df2 = df2.drop_duplicates(subset=['Food'])
# For each row in df1, find the best match in df2
df1['best_match'] = df1['Food'].apply(lambda x: process.extractOne(x, df2['Food'].tolist()))
df1['best_match'] = df1['best_match'].apply(lambda x: x[0])
# Only keep the columns from df2 that we want in our merged dataframe
df2 = df2[['Food', 'Jan Quantity']]
# Merge df1 to df2 on the best_match column
merged_df = df1.merge(df2, left_on=['best_match'], right_on=['Food'], how='left')
# Remove columns used for matching that we no longer need
merged_df = merged_df.drop(columns=['Food_y', 'best_match'])Common mistakes when using INDEX MATCH in Python#
Since there isn't a built in INDEX MATCh function in Python, you might run into errors or data discrepancies when trying to perform an INDEX MATCH in Python. Here are some common mistakes to watch out for:
Incorrect Merge Type#
Using the wrong type of join (left, right, inner, outer) during merging can lead to missing or unexpected data.
Most of the time, you'll want to use a left join, which will keep all rows from the left DataFrame and only include matching rows from the right DataFrame.
Not Deduplicating Data Before Merge#
If you are merging data from two different dataframes, in order to replicate Excel's INDEX MATCH behavior, you'll need to deduplicate second dataframe on the key column(s) This is because Excel's INDEX MATCH will return the first match it finds, even if there are multiple matches, wherease, pandas' merge will return one row for each match.
To deduplicate a dataframe, use the `drop_duplicates` method.
# Deduplicate df2 on the key column(s)
df2 = df2.drop_duplicates(subset=['key'])Key Column Data Type Mismatch#
Trying to match columns with different data types will likely cause an error. For example, if you use a key column with a string data type in one dataframe and a key column with an integer data type in another dataframe, you'll get the following error: `ValueError: You are trying to merge on object and int64 columns. If you wish to proceed you should use pd.concat`.
If your key columms have different data types, it might be a sign that those columns should not be used for merging, ie: they are not a common identifier of data in both dataframes. However, if they are a common identifier, you'll need to adjust the data types before merging.
To convert a column of strings to integers, use the `astype` method.
# Convert the key column in df1 to an integer data type
df1['key'] = df1['key'].astype(int)Expecting Case Insensitive Matching by Default#
By default, Excel INDEX MATCH is case-insensitive, whereas pandas merging is case-sensitive. If case-insensitive matching is needed, adjust your key columns to be of the same case (either lower or upper) before merging.
To do so, you can use the `str.lower` or `str.upper` methods and then apply the `merge` method.
# Convert the key columns to lowercase
df1['key_lower'] = df1['key'].str.lower()
df2['key_lower'] = df2['key'].str.lower()
# Merge df1 and df2 on the lowercase key column
result = pd.merge(df1, df2, on='key_lower', how='left')Understanding the Lookup and Match Formula in Excel#
The INDEX MATCH combo in Excel is used to search for a value in one column (using MATCH) and then return a corresponding value from another column (using INDEX).
=INDEX(array, MATCH(lookup_value, lookup_array, [match_type]), [column_num])
INDEX MATCH Excel Syntax
| Parameter | Description | Data Type |
|---|---|---|
| array | The range from which you want to return a value from. | range |
| lookup_value | The value you want to search for. | value |
| lookup_array | The range where you want to search for the lookup_value. | range |
| match_type | The type of match you want to perform. 1 (default) for appoximate match, 0 for exact match. | number |
| column_num | The column number from which you want to return a value from. | number |
Examples
| Formula | Description | Result |
|---|---|---|
| =INDEX(B2:B10, MATCH("apple", A2:A10, 0)) | Return the value from column B where column A has 'apple'. | Value corresponding to 'apple' |
| =INDEX(B2:D10, MATCH("apple", A2:A10, 0), MATCH("price", B1:D1, 0)) | Searche for the row where 'apple' is found in the range A2:A10 and the column where 'price' is found in the range B1:D1, then returns the intersecting cell's value from the range B2:D10. | The intersection of the 'apple' row and 'price' column |
Get answers from your data, not syntax errors. Download the Mito AI analyst
Don't want to re-implement Excel's functionality in Python?
Edit a spreadsheet.
Generate Python.
Mito is the easiest way to write Excel formulas in Python. Every edit you make in the Mito spreadsheet is automatically converted to Python code.
View all 100+ transformations →